I had 2 doubts regarding dask dataframe API
-
Is there any difference between dataframe apply and map_partitions functions in terms of performance?
-
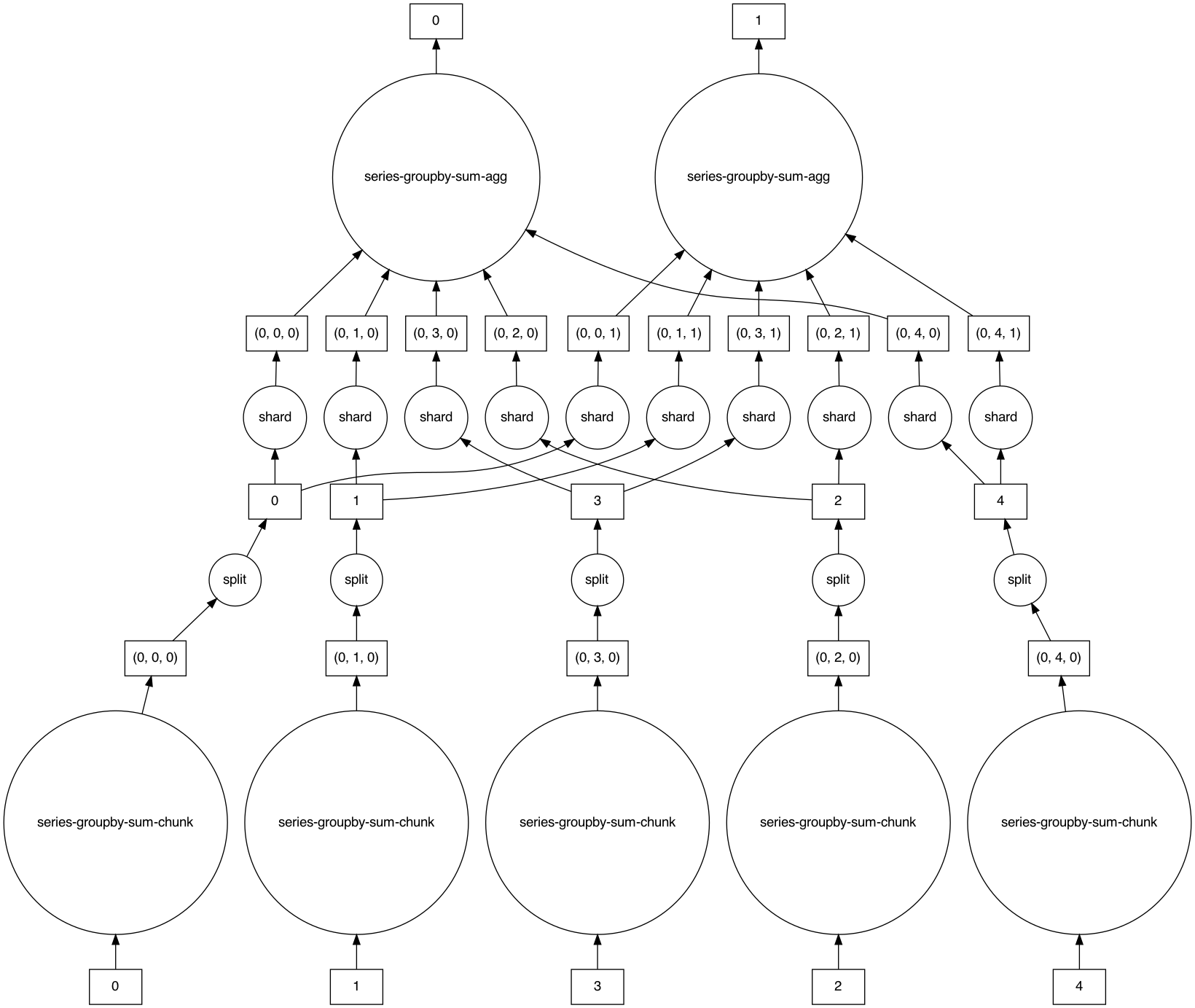
df.groupby(‘reviewerID’)[‘overall’].count(split_out=4, split_every=False) : what do the split_out and split_every arguments signify? I could not get the details about the arguments from the documentation.
@vigneshn1997 Those are both good questions!
apply calls map_partitions internally, so they should both give you similar performance.
As for split_out and split_every:
- For some context, Dask’s task graphs have a reduction step for
groupby aggregations.
-
split_out lets you set the number of partitions your output should have, and
-
split_every helps Dask to compute how many layers there are in the tree (more concretely, each parent node, will have at most the number of children defined by split_every).
Note that you wouldn’t need to tune these manually in most cases.
Here is an example that shows the task graphs generated by using these:
import pandas as pd
import dask.dataframe as dd
df = pd.DataFrame({'x': [1,2,1,2,1,2,1,2,1,2], 'y': range(10)})
ddf = dd.from_pandas(df, npartitions=5)
a = ddf.groupby('x').y.sum()
a.visualize()
b = ddf.groupby('x').y.sum(split_out=2)
b.visualize()
c = ddf.groupby('x').y.sum(split_every=3)
c.visualize()
Thank you @pavithraes for the detailed answer. This is really helpful for me.