I was trying to use the sample method to shuffle a dask dataframe (as suggested in Shuffle and shard dask dataframe). But the shuffling is happening only within a partition, not between partitions.
I even tried random_split with shuffle=True and also the shuffle method, But all methods are shuffling within a partition.
How can I shuffle a dask dataframe between partitions too?
This is what I did:
a = [i for i in range(100)]
b = [i/10.0 for i in range(100)]
c = [i/100.0 for i in range(100)]
pd_df = pd.DataFrame(list(zip(a, b, c)),
columns =['a', 'b', 'c'])
dd_df = dd.from_pandas(pd_df, npartitions=2)
shuf_df1 = dd_df.sample(frac=1)
both dd_df and the shuffled df partitions and having the same statistics which shows shuffling is done only in a partition and not across partitions
Shuffling is an expensive operation in Dask, that’s why data isn’t moved across partitions automatically.
I found this shuffle() documentation that may be helpful for you, but I’ll keep looking into it.
@vigneshn1997 I think you can use sort_values after sample(frac=1) to move rows between partitions (which calls shuffle internally):
import numpy as np
import pandas as pd
import dask.dataframe as dd
df = pd.DataFrame({'x': range(10)})
ddf = dd.from_pandas(df, npartitions=3)
# Create a column with random values
ddf['random'] = ddf.apply(lambda x: np.random.randint(0, ddf.npartitions), axis=1)
# Sort by random values (which shuffles the DataFrame)
ddf_new = ddf.sort_values('random')
ddf_new.compute()
Would this help?
@pavithraes Thank you I will try this out. On these lines I was thinking one more idea,
Lets say I have 8 data points and have to create 4 partitions,
I created an array with values [0, 0, 1, 1, 2, 2, 3, 3] and shuffled the array (arr[i] tells me which partition the data point belongs to)
I am not able to assign this array as a new column to the dataframe on which I can call sort on.
I can assign a list as a column easily using pandas dataframe but not using dask dataframe.
I tried to match the divisions too of the original df and this list dataframe but still was getting errors. Is there a way to assign a new column to a dask dataframe other than the apply method. I am not able to fit this in the apply function design
I tried this out, and observed that after calling sort_values, checking the size of the dataframe ddf_new, it is consistent with the size of df. But when I compute the length of individual partitions and sum up the partition lengths it is not consistent with the size of the dataframe. Why could this be the case?
I had a 3000 length dataframe, sometimes after shuffling I got size as 2947, sometimes I got 3015.
@vigneshn1997 Thanks for the questions!
I can assign a list as a column easily using pandas dataframe but not using dask dataframe.
Dask doesn’t support this directly, you’ll need to convert the list into a Dask DataFrame Series, and then assign it. Continuting my previous example, something like:
r = [0, 0, 0, 1, 1, 2, 2, 2, 3, 3]
ddf['random']= dd.from_pandas(pd.Series(r), npartitions=2)
But when I compute the length of individual partitions and sum up the partition lengths it is not consistent with the size of the dataframe. Why could this be the case?
That’s odd indeed. I’m not able to reproduce this, could you please share a minimal, reproducible example that shows this behaviour?
The minimum reproducible example:
import numpy as np
import pandas as pd
import dask.dataframe as dd
df = pd.DataFrame({'x': range(150)})
ddf = dd.from_pandas(df, npartitions=1)
big_df = dd.concat([ddf]*20)
big_df = big_df.repartition(npartitions=4)
big_df['random'] = big_df.apply(lambda x: np.random.randint(0, big_df.npartitions), axis=1)
ddf_new = big_df.sort_values('random').repartition(npartitions=4)
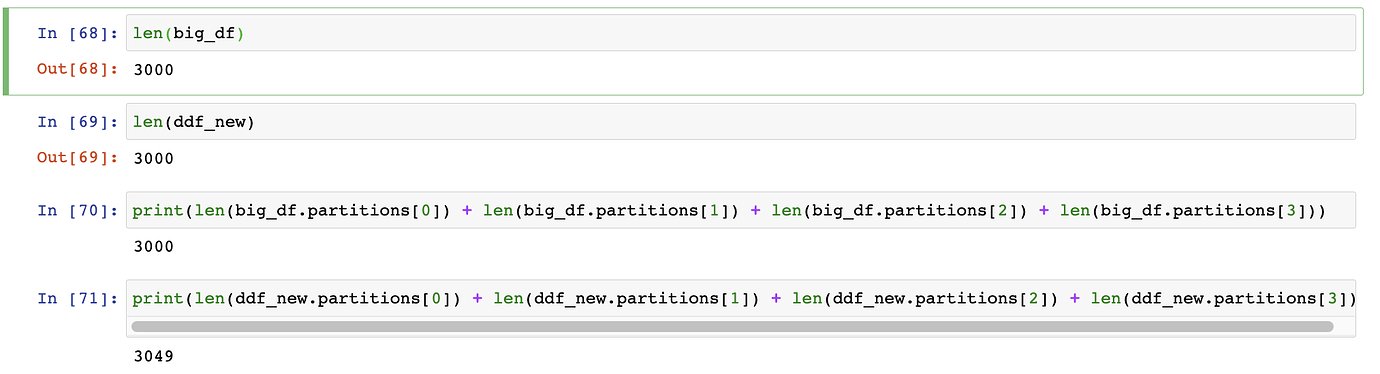
len(big_df) #3000
len(ddf_new) #3000
print(len(big_df.partitions[0]) + len(big_df.partitions[1]) + len(big_df.partitions[2]) + len(big_df.partitions[3])) #3000
print(len(ddf_new.partitions[0]) + len(ddf_new.partitions[1]) + len(ddf_new.partitions[2]) + len(ddf_new.partitions[3])) #3049 <- this is changing
@vigneshn1997 Thanks for the example!
When you call len, the elements of the big_df['random'] column are generated, sorted, and then the dataframe is repartitioned. Hence, the number of elements in each partition of ddf_new will depend on the random numbers generated, which will change each time you call len.
To elaborate, try executing the following multiple times, you’ll notice the partition sizes changing:
ddf_new.map_partitions(len).compute()
This is what happens when you call:
print(
len(ddf_new.partitions[0]) +
len(ddf_new.partitions[1]) +
len(ddf_new.partitions[2]) +
len(ddf_new.partitions[3])
)
len(ddf_new.partitions[0]), len(ddf_new.partitions[1]), etc., are being computed on different dataframes. Does that make sense?
To avoid this, you can persist ddf_new. Dask will evaluate this line and store it in memory, hence the random numbers will be generated only once, and you’ll get consistent results:
ddf_new = big_df.sort_values('random').repartition(npartitions=4).persist()
print(
len(ddf_new.partitions[0]) +
len(ddf_new.partitions[1]) +
len(ddf_new.partitions[2]) +
len(ddf_new.partitions[3])
)