I’m trying to run a dask.delayed function which is highly computationally- and memory-intense and therefore prone to OOM crashed and over-utilization errors if not scheduled properly.
I’m creating dask.delayed functions and gathering them non-asynchronously to avoid over-utilization:
import dask
import pandas as pd
@dask.delayed
def intense_func(arg1): # very large inputs (objects containing datasets)
# do some intense work
return pd.DataFrame(...) # very small output (only one row)
runs=10
# 8-core machine
num_workers=2
threads_per_worker=4
cluster = LocalCluster(
n_workers=num_workers,
threads_per_worker=threads_per_worker,
resources = {'foo':1},
processes=False,
)
client = Client(cluster)
task_graph = []
for run in range(runs):
# generate dataset based on random parameters
irand1,irandn,jrand1,jrandn,krand1,krandn = np.random.randn(...)
subvolume = volume[irand1:irandn,jrand1:jrandn,krand1:krandn]
task_graph.append(intense_func(subvolume))
df = dask.compute(*task_graph, resources={'foo':1}) # 'foo' doesn't seem right, but it doesn't nicely without it ¯\_(ツ)_/¯
df = pd.concat(df).reset_index(drop=True)
Currently, the program is successfully scheduling the functions to run synchronously (i.e. No worker is running more than one task at a time). However, these are being spawned on different processes, causing memory to accumulate and crash the machines with an OOM error. (Related note: I get errors like this: distributed.utils_perf - WARNING - full garbage collections took 17% CPU time recently (threshold: 10%) before failure).
I currently have a task graph that has tasks being spawned on different processes, but successfully not executing more than two processes at a time. This only solves the issue of over-utilization, but I actually want something like this:
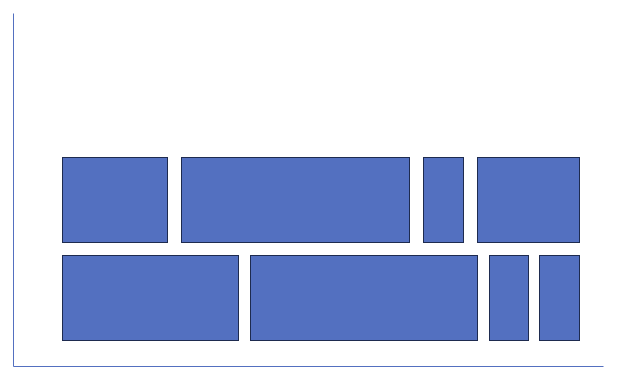
Which would probably also solve the OOM errors. Is it possible to only allow Dask to spawn two workers, and only allow these two workers to do the work, without creating new processes beyond these two workers?
Thanks in advance ![]()
(Originally posted here: python - Dask: How to submit jobs to only two processes in a LocalCluster? - Stack Overflow)

