As far as I know, when calling client.submit(…,priority=-10), that task has lower priority than when calling client.submit(…,priority=10).
However, when browsing through the workers in the Dask dashboard (attached image), I see that the tasks that were called with priority=-10 show up as having priority (10,n,0), while tasks that were submitted with priority=10 show up as having priority (-10,n,0).
Is this something to worry about or am I just misunderstanding this functionality?
Are the tasks in the ‘Processing’ table in order of priority or do the numbers on the Priority tuple matter for this decision?

Hi @byrom771,
Yes, from the API documentation:
Optional prioritization of task. Zero is default. Higher priorities take precedence
Do you have a reproducer for this? Are the task you are submitting respecting the priority you set?
I’m also encountering the same issue. I have a similar setup:
- Create a LocalCluster with N+M workers
- Main thread creates N outer workers (futures) with (say)
priority = -10 - Each of these workers create M inner workers (futures) with
priority = +10
The idea is: Inner workers should finish first and return the results to outer workers, so they can work on them. After all inner worker’s tasks finish, the outer task can also finish.
But this causes deadlocks at the end, probably because the priorities got reversed. I’m not sure if it is per design, to make + priorities as high in user API, but use Linux-style internally, and this is what we see in the Dashboard (like provided by OP). If it is not by design, -10 becomes +10 and +10 becomes -10 somewhere - so deadlock can occur.
Deadlock case:
- 2 outer workers (say “O1”, “O2” tasks), 12 inner workers (say .“O1-123” style tasks, but many)
- The scheduler distribute them, so some workers have both outer and inner tasks
- At the end two workers remain unfinished (50% chance), each having two tasks:
Wx: O1, O2-234
Wy: O2, O1-543
So, if it were working correct, O1-543 and O2-234 with high priorities would finish first, then O1 and O2 can finish.
But because the priorities are not correct (?) somehow, O1 & O2 has precedence and the workers never finish because of deadlock.
In the next runs I’ll try them reversed…
I ran more processes, and although I reversed the priorities, deadlocks are still happening. It can also occur for a single language on a single last worker, like:
Wx: O1, O1-543
Here is the results of a run of 17 datasets where a single worker is left in deadlock.

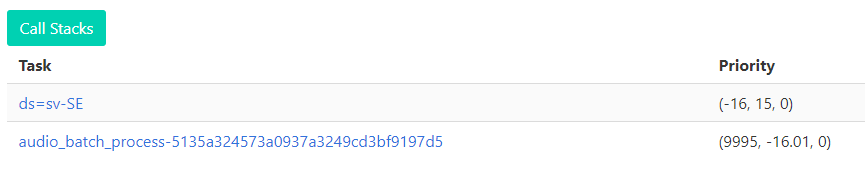
Here “audio_batch_process-xxx” must be finshed to finish ds=sv-SE dataset, but gets stuck. It is obvious here, but for multiple stuck workers, I just infer the deadlock as the naming is cryptic.
In the above run, I gave positive priorities for the outer (datasets, ds=sv-SE in this case), and negative for sub processes (although reverse of documentation, I wanted also test this, as it is also happening the other way around). As you can see in this last image, the polarities are reversed.
Because of such deadlocks, I need to run each set twice to clean such cases (last batch at least).
What do the 3 numbers mean under the priority column?
could you provide some code to reproduce - in general you can change the config in dask to run a different multiprocessing context to spawn or forkserver.
also please show the graph it self, as deadlocks in dask arise primarily from circular dependencies and improper resource management.
Just beware of the termes yous use, there is some confusion between Workers and Taks.
If you are launching tasks from task, isn’t the following what you are looking for: Launch Tasks from Tasks — Dask.distributed 2024.9.0 documentation.
Anyway, I’ll dig about in this priority question and get back to you.
Okay, I just tested the behavior with this basic example:
from distributed import Client
import time
client = Client()
def low_prio(x):
time.sleep(10)
print(f"end low prio {x}")
def high_prio(y):
time.sleep(2)
print(f"end high prio {y}")
low_prio_futures = client.map(low_prio, range(10), priority=-10)
time.sleep(0.5)
high_prio_futures = client.map(high_prio, range(20), priority=10)
This is how the task graph ends:

You can see that at first, two low_prio tasks are scheduled on each Worker, but then high_prio tasks take precedence, and the final low_prio tasks are executed afterwards.
You could have assumed that after the first low_prio tasks there would have been directly high_prio tasks executed, but I guess once a task is queued on a Worker, nothing really moves.
I think the behavior is allright with the priority mechanism.
Just got a problem of connexion to the Dashboard, but the priority tuple displayed is internal, and I guess values are working opposite from what you give in argument.
Sorry, my computer (and myself) is running 24/7 so I could not compile a sample code. The workflow is not simple, I need to explain with code and comments, but is is not easy to simulate it with simple code, let alone creating a reproducible one, because it is not deterministic and happens after many data moves. I cannot calculate the frequency exactly, about but 1/3 - 1/10 of the time.
isn’t the following what you are looking for: Launch Tasks from Tasks — Dask.distributed 2024.9.0 documentation.
Yep, similar workflow with some pre-processing.
The idea is: Inner workers should finish first and return the results to outer workers, so they can work on them. After all inner worker’s tasks finish, the outer task can also finish.
Just beware of the termes yous use, there is some confusion between Workers and Taks.
You are right, I don’t have a confusion but my writing is bad (after hours).
Inner workers should finish first === Workers running inner tasks should finish them first
I’ll try to create some code.
Thank you for this remark!
I think (and hope) that was it. I had (leftover) resources={"outer": 1, "inner": 1} style in Cluster definition and still requesting one or the other in the client.submit() calls. I was trying to control distribution of outer and inner tasks to their designated workers (“outer-workers” and “inner-workers” - also reason of my terminology mix above)
I removed them and it is running without any hick-ups in the last 20 or so runs (fingers crossed).
So, when dask sees some resource definition/request, as all M+N workers have both “inner” and “outer” resource, it was pushing inner jobs to workers which already has outer jobs, thus creating deadlocks in some random cases, where each depend the other.
If there are no such definition, it tends to keep things together (seems so), i.e. assigns new outer tasks to the same worker other outer task resides, like below (1st and 4th bars are for datasets/outer tasks, others are inner tasks):

(don’t mind the white areas, we scan/skip file content there)
In the meantime, I also reviewed the priorities, and gave them decreasing values in time, to force some first-come-first-served action.
Unfortunately, it happened once again, after 35 runs or so. As I’m doing this interactively 5-20 datasets at a time, I can deal with it for now.
that is strange behavior - can you share some code example? ![]()
What I don’t understand here: are you using worker_client() context manager? You shouldn’t run into deadlocks if so.